How to Add Memory to AI Chatbots: From Goldfish 🐠 to Elephant 🐘

Imagine trying to have a conversation with someone who has absolutely no recollection of anything you've said before - not even from 2 seconds ago. Welcome to the world of Large Language Models!
The Memory Problem 🤔
LLMs, despite being very smart, have one big problem they're essentially stateless they can't remember anything. Each time you send a message, it's like starting a brand new conversation. This leads to some hilariously frustrating scenarios:
Human: My name is Spandan!
Bot: Nice to meet you, Spandan!
Human: What's my name?
Bot: I'm not sure, you haven't told me your name yet!
This happens because LLMs don't maintain any state between requests. Each prompt is processed independently, making it impossible for the model to remember previous interactions without some help from us. It's like having a super-intelligent goldfish - brilliant in the moment, but with zero recall of the past!
So how do we fix this memory problem? Let's evolve our chatbot through three stages of memory development, from goldfish to elephant! 🐠 → 🐹 → 🐘
Get the Code 💻
Ready to build your own memory-enhanced chatbot? All the code from this tutorial is available in our GitHub repository:
🔗 github.com/spandan114/building-intelligent-chatbots
Level 1: The Goldfish Bot 🐠 (No Memory)
Our first bot is like a digital goldfish - living entirely in the present moment. Here's what it looks like:
def main():
st.title("💬 Chatbot with Memory")
llm = ChatGroq(
model="gemma2-9b-it",
groq_api_key=os.getenv("GROQ_API_KEY")
)
prompt = ChatPromptTemplate.from_messages([
("system", "You are a helpful assistant please answer the question."),
("human", "{input}")
])
chain = prompt | llm
if prompt := st.chat_input("What would you like to know?"):
response = chain.invoke({"input": prompt})
st.markdown(response.content)
This bot treats every message as if it's the first one it's ever seen. It's like trying to have a conversation with someone who hits the "refresh" button on their brain every few seconds - "Nice to meet you!" "But... we just met 5 seconds ago!" 🔄 Entertaining perhaps, but not exactly what you want in a helpful assistant!
Level 2: The Hamster Bot 🐹 (Temporary Memory)
Let's upgrade our bot with some short-term memory. Like a hamster storing seeds in its cheeks, this bot can remember things... at least until you close your browser!
store = {}
def get_session_history(session_id: str) -> BaseChatMessageHistory:
if session_id not in store:
store[session_id] = ChatMessageHistory()
return store[session_id]
@st.cache_resource
def init_chat_chain():
llm = ChatGroq(
model="gemma2-9b-it",
groq_api_key=os.getenv("GROQ_API_KEY")
)
prompt = ChatPromptTemplate.from_messages([
("system", "You are a helpful assistant please answer the question."),
("human", "{input}")
])
chain = prompt | llm
return RunnableWithMessageHistory(
chain,
get_session_history,
)
The magic here happens through:
A simple dictionary (
store) that keeps track of conversationsChatMessageHistorythat maintains messages for each sessionRunnableWithMessageHistorythat automatically handles message history
But remember - this memory only lasts as long as your server is running. Refresh the page, and poof! 💨 All memories vanish like your motivation on Monday mornings.
Level 3: The Elephant Bot 🐘 (Permanent Memory with Pinecone)
Now we're entering big brain territory! Let's give our bot a memory that would make an elephant jealous using Pinecone as our long-term storage solution.
First, we need some helper functions to handle message serialization:
def serialize_message(msg: BaseMessage) -> dict:
"""Serialize a LangChain message to a dictionary."""
return {
"type": msg.__class__.__name__,
"content": msg.content,
}
def deserialize_message(msg_dict: dict) -> BaseMessage:
"""Deserialize a dictionary to a LangChain message."""
msg_type = msg_dict["type"]
if msg_type == "HumanMessage":
return HumanMessage(content=msg_dict["content"])
elif msg_type == "AIMessage":
return AIMessage(content=msg_dict["content"])
else:
raise ValueError(f"Unknown message type: {msg_type}")
Pinecone Setup:
Step 1: Setting Up Your Pinecone Account 📝
Head over to Pinecone's website and create an account
Once logged in, create a new project
Grab your API key from the console - you'll need this for authentication
Step 2: Create Your Index 📊
In Pinecone's console, create a new index with these specific
# Index Configuration
Name: chat-memory
Dimensions: 1536 # For OpenAI's text-embedding-3-small model
Metric: cosine # Best for semantic similarity
Then, the star of the show - our PineconeMemory class:
class PineconeMemory:
def __init__(self):
# Initialize Pinecone with your API key
self.pc = Pinecone(api_key=os.getenv("PINECONE_API_KEY"))
self.index = self.pc.Index("chat-memory")
# Set up OpenAI embeddings
self.embeddings = OpenAIEmbeddings(
model="text-embedding-3-small",
openai_api_key=os.getenv("OPENAI_API_KEY")
)
# Initialize vector store
self.vector_store = PineconeVectorStore(
index=self.index,
embedding=self.embeddings,
text_key="text",
namespace="chat_history"
)
The real magic happens in two key methods:
- Saving Memories 🖊️:
def save_history(self, session_id: str, history: ChatMessageHistory):
# Convert chat history to storable format
history_data = {
"messages": [serialize_message(msg) for msg in history.messages],
"session_id": session_id
}
# Create a document for storage
document = Document(
page_content=json.dumps(history_data),
metadata={"session_id": session_id}
)
# Save to Pinecone
self.vector_store.add_documents([document])
- Retrieving Memories 📖:
def get_session_history(self, session_id: str) -> BaseChatMessageHistory:
# Search for relevant history
results = self.vector_store.similarity_search(
session_id,
filter={"session_id": session_id},
k=3 # Get last 3 relevant histories
)
# Reconstruct chat history
history = ChatMessageHistory()
if results:
for result in reversed(results):
history_data = json.loads(result.page_content)
for msg_dict in history_data["messages"]:
msg = deserialize_message(msg_dict)
history.messages.append(msg)
return history
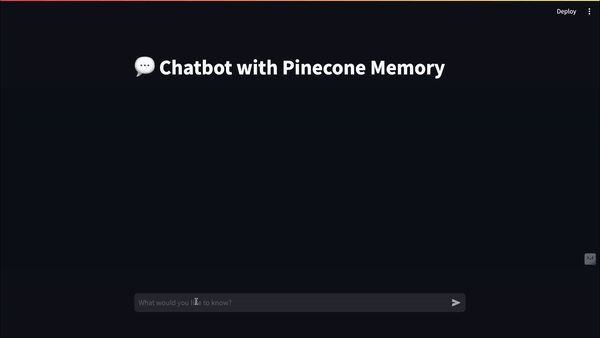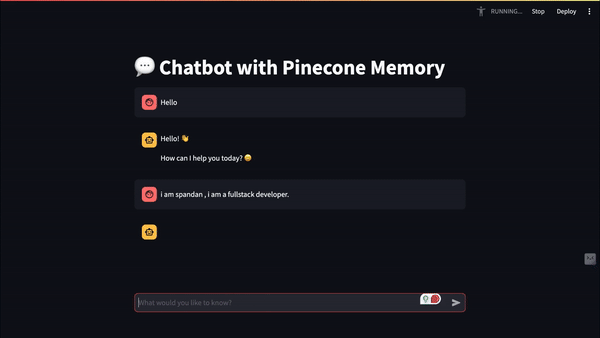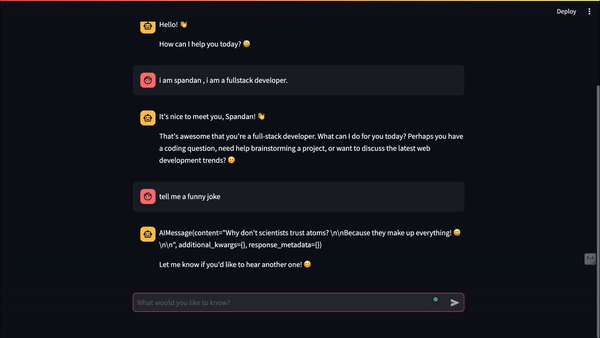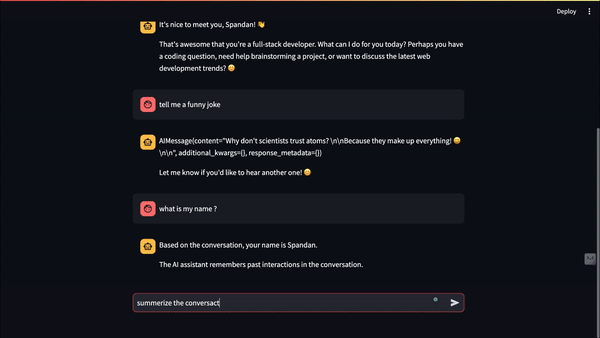
Final Result: Meet Our Elephant-Memory Chatbot! 🐘
Here's what our memory-enhanced chatbot can do:
Why This Works So Well 🎯
Vector Magic: Instead of just storing text, we convert conversations into mathematical vectors that capture the semantic meaning of messages.
Efficient Retrieval: Pinecone's similarity search helps us quickly find relevant past conversations.
Scalability: As your bot talks to more users, Pinecone handles the growing memory needs efficiently.
The Complete Picture 🖼️
Here's how it all comes together in the main application:
def main():
st.title("💬 Chatbot with Pinecone Memory")
# Initialize chat chain and memory
chat_chain, memory = init_chat_chain()
if prompt := st.chat_input("What would you like to know?"):
# Process user input
st.session_state.messages.append({"role": "user", "content": prompt})
# Get bot response
config = {"configurable": {"session_id": st.session_state.session_id}}
response = chat_chain.invoke({"input": prompt}, config=config)
# Save the conversation
history = memory.get_session_history(st.session_state.session_id)
history.add_user_message(prompt)
history.add_ai_message(response.content)
memory.save_history(st.session_state.session_id, history)
Conclusion 🎬
We've successfully evolved our chatbot from a forgetful goldfish to a wise elephant with a memory that persists across sessions and server restarts. The key ingredients were:
Understanding the stateless nature of LLMs
Implementing temporary memory for basic conversation tracking
Using Pinecone for sophisticated, permanent storage
Proper serialization and deserialization of messages
Efficient retrieval of relevant conversation history
Remember, with great memory comes great responsibility! Make sure to handle user data appropriately and keep your elephant's memory clean and well-organized.
